At its HasuraCon ’22 conference, Hasura today announced the early release of a software development kit (SDK) that extends the reach of its GraphQL platform to additional data sources.
In addition, Hasura is making generally available integrations with the GitHub repository, support for OpenTelemetry Traces within the Hasura Cloud Platform and Microsoft SQL event triggers.
Finally, Hasura Cloud can now be deployed on the Google Cloud Platform while the Hasura Cloud Enterprise edition is now available on the Amazon Web Services (AWS) marketplace.
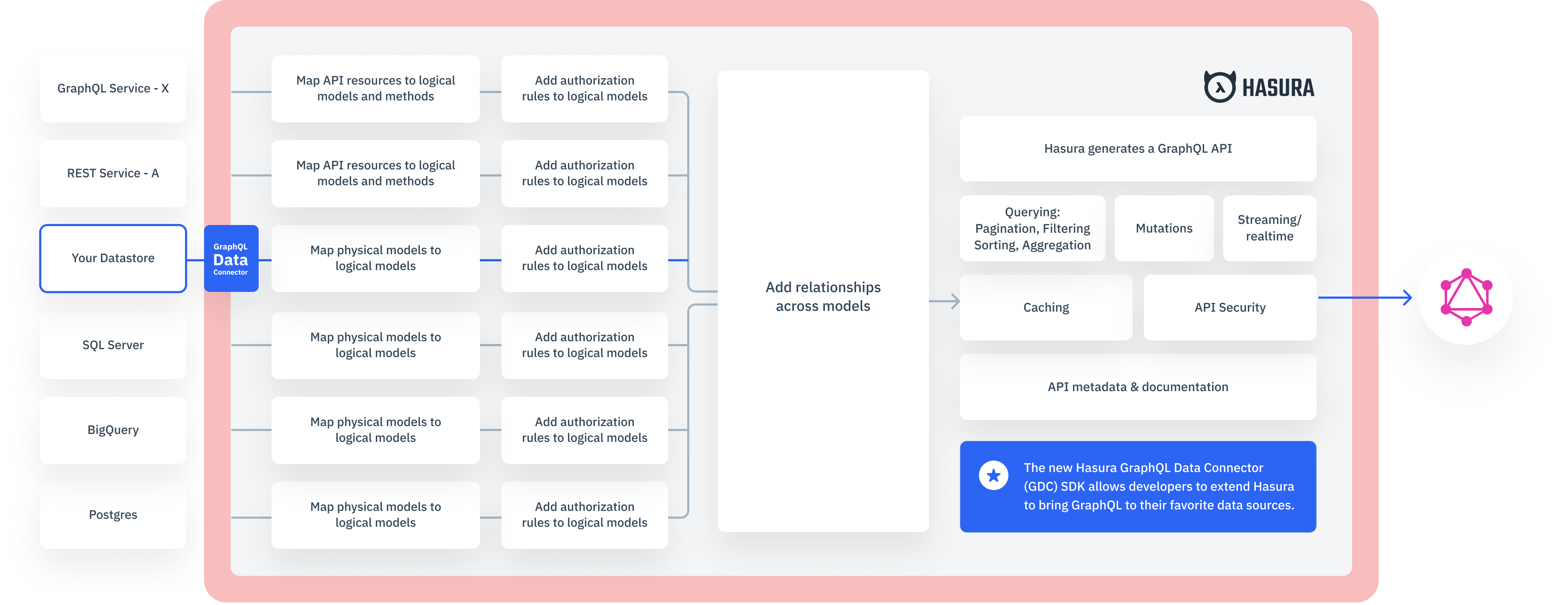
Hasura CEO Tanmai Gopal said that while the company already provides support for widely used data sources such as the Postgres database, there are many data sources that organizations also want to be able to query via GraphQL application programming interfaces (APIs). Organizations want to be able to join data using GraphQL regardless of what repository it resides in, he added.
The open source Hasura engine at the core of the company’s offerings automatically generate a GraphQL schema from a data source. That can then be used to accelerate the development of APIs to make it easier for a wider range of developers to build applications that aggregate data across multiple sources.
That approach eliminates the backend complexity that IT teams encounter when adding GraphQL APIs to an application environment that already has a range of APIs for internal IT teams to support, noted Gopal.


GraphQL was originally created by Facebook, but it’s still not clear to what degree GraphQL APIs will supplant REST APIs. Developers tend to prefer GraphQL APIs because they provide more granular control over what data is accessed. The challenge is the number of backend services that expose GraphQL APIs is still comparatively limited.
It’s not likely IT teams will replace REST APIs with GraphQL-based APIs overnight, but the percentage of new applications that rely on GraphQL APIs will steadily increase. Overall, the number of APIs employed within IT environments is rapidly expanding as more microservices-based applications are deployed. Each microservice generates its own API. Over time, IT teams will find themselves managing a wider variety of types of APIs.
The challenge is that it’s not always clear who within IT organizations will manage those APIs. They are often created by developers and are left to IT operations teams to maintain. It’s not uncommon for IT teams to find themselves managing hundreds, perhaps thousands of APIs.
In addition, many of those organizations are now consuming data via APIs exposed by other organizations. Over time, the level of interdependency between APIs and applications will serve to make application environments much more complex to manage.
In the meantime, DevOps teams will need to extend existing DevOps workflows to both support and secure GraphQL-based APIs. The amount of sensitive data being accessed via those APIs is likely to accelerate the rate at which organizations are adopting DevSecOps best practices. Let’s hope this happens before they wake up to discover GraphQL APIs have already proliferated across the enterprise.
